Kaled.
I use my experience and skills in data engineering, science, analytics, and cloud computing;
To build and manage Data pipelines, CLoud Infrastructure, Databases, and Data Warehouses.
To build and manage Data pipelines, CLoud Infrastructure, Databases, and Data Warehouses.


My background and experience allow me to perform in data engineering, AWS Cloud, data modeling, analytics, machine learning, and data science.
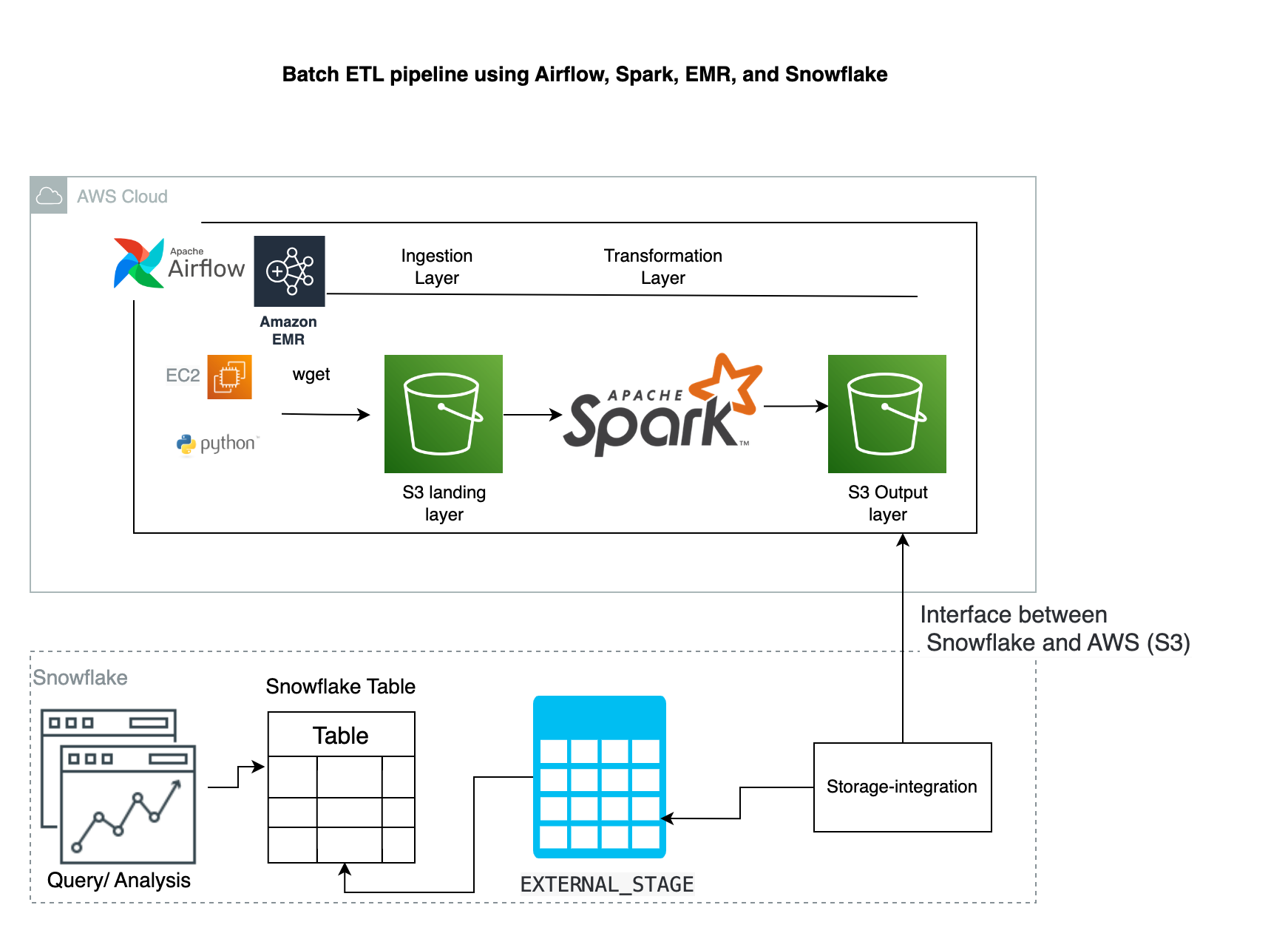
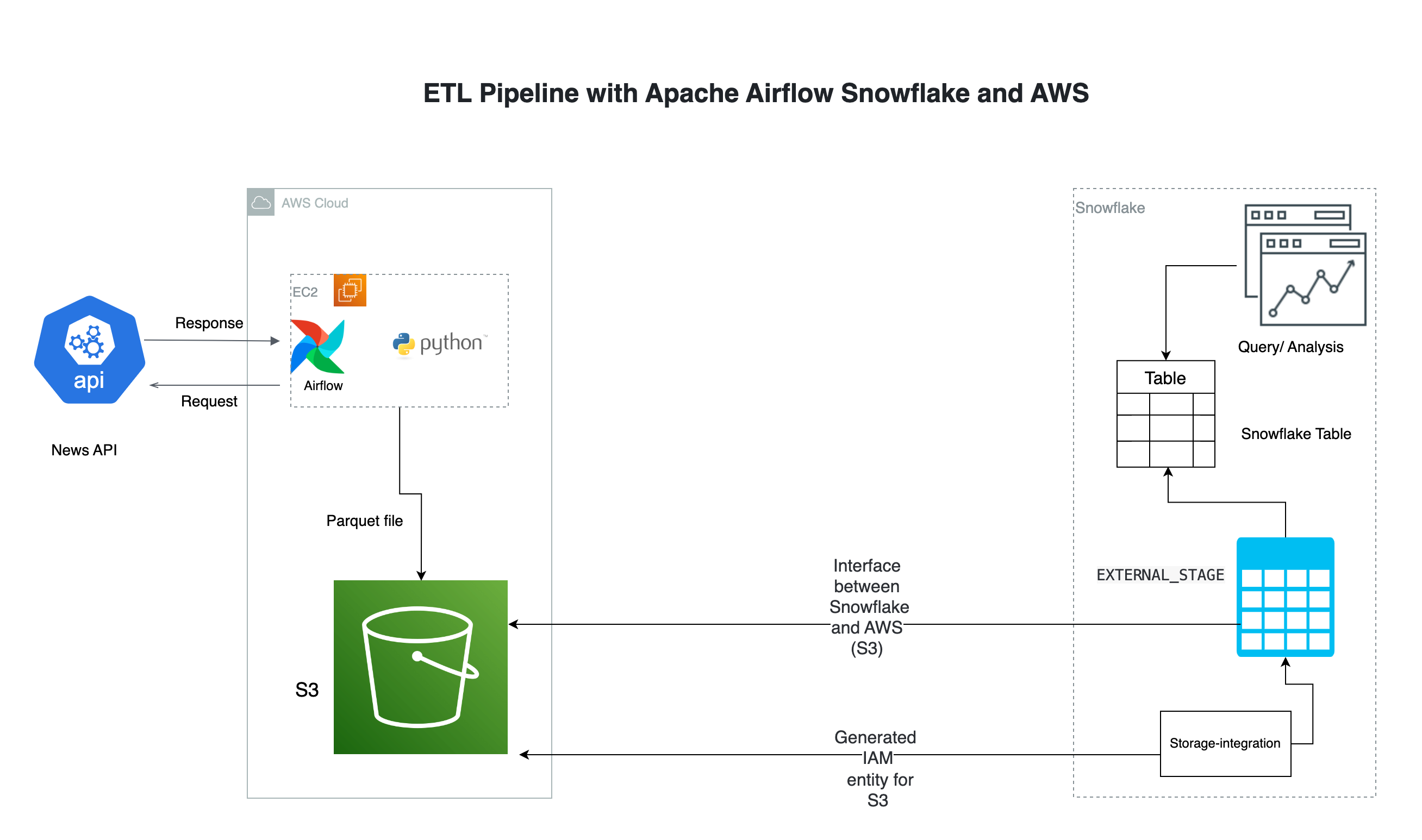
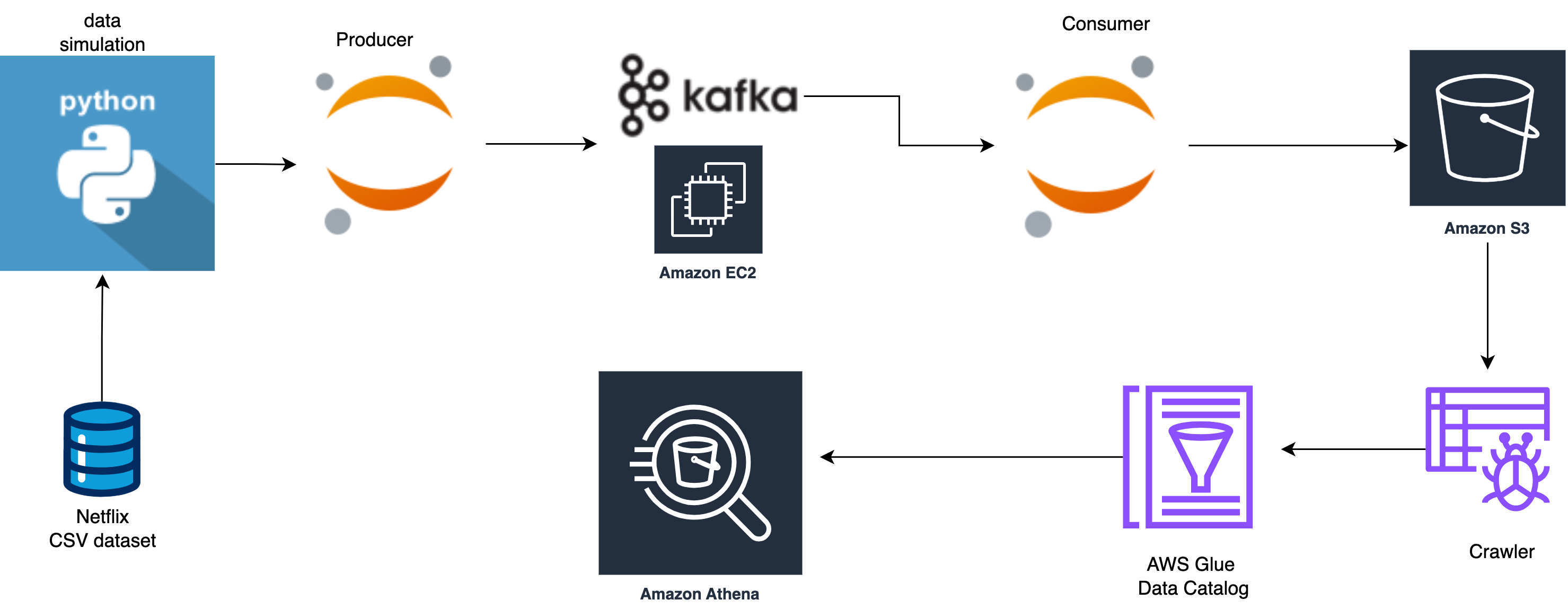
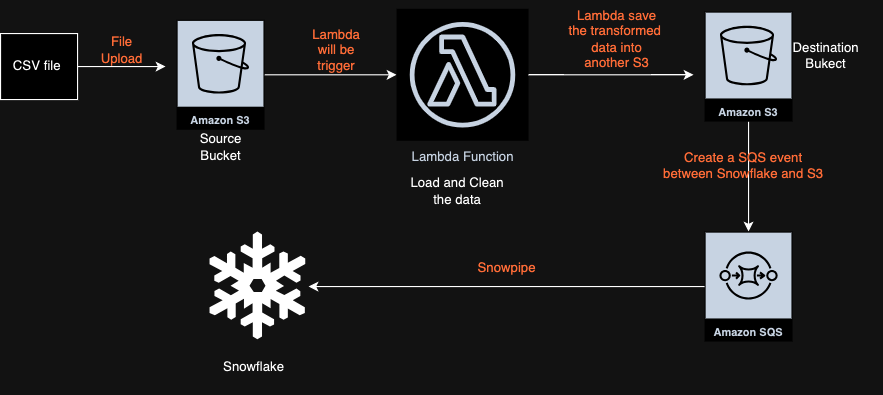
My expertise includes building a data pipeline, database, data warehouse, analyzing, machine learning model, relational and non-relational databases like MySQL, PostgreSQL, HBase, AWS Redshift, AWS DynamoDB, AWS Aurora, AWS RDS as well as big data solutions like Hadoop, Apache Spark, AWS EMR.
Here are a few technologies I've been working with recently:I worked as a data manager and also developed web applications.
I worked as an AWS data engineer freelancer, where I worked with some small companies to manage their data.
I worked as a Data Engineer/ software Engineer where I was building and managing data pipeline and websites.
I was working at Zolors as a Web Developer.